
How large language models process text


Ever wondered how your favorite Large Language Models (LLMs), such as ChatGPT or Cloud Code, work? You certainly don’t need to have a PhD in data science to figure that out. However, this knowledge will make you more effective in using such models. And this is what we will cover in this article
Any text-processing machine learning model, whether it’s a large language model (LLM) or a highly specialized small language model (SLM), relies on a technology known as Natural Language Processing (NLP).
While language comes naturally to us, it’s much harder for machines to understand. That’s where NLP comes in. It helps computers make sense of human language, bridging the communication gap between people and technology.
NLP is more than just a technical feat. It’s a dynamic interplay between linguistics, statistics, and computer science. To understand NLP, it’s helpful to appreciate the dual nature of language: it operates on both structure (grammar and syntax) and meaning (semantics). NLP works to capture both aspects, enabling machines to make sense of not just what is being said but also the context and intent behind it.
With structured data, NLP applies machine learning and deep learning models to perform various language tasks. Supervised learning methods can classify sentiment, identify topics, or predict the next word, while deep learning architectures, such as recurrent neural networks (RNNs) and transformers, allow for more advanced tasks like language translation, summarization, and text generation.
The base unit of NLP is a token, but there’s much more to it. Let’s dive into more detail to see how NLP works.
How NLP works
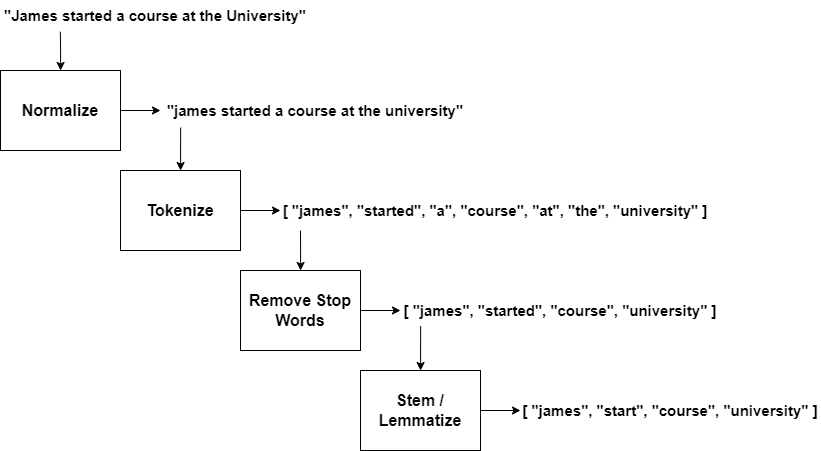
Before machines can interpret language, they need a structured, digestible form of the input. This involves processes such as tokenization (breaking down sentences into individual words or tokens), stop-word removal (eliminating common, less meaningful words like “the” or “is”), and stemming or lemmatization (reducing words to their base forms). Preprocessing is the foundation that allows for accurate analysis and interpretation. This process is shown in the following figure:
The next step, text analysis, then dives into grammar, structure, and word relationships. It involves parsing sentences, identifying parts of speech, and understanding syntactic structures. Analyzing sentence structure is vital for tasks like named entity recognition (identifying names, places, dates, etc.) and dependency parsing (identifying relationships between words).
To make language comprehensible to a machine, text must be transformed into numerical data. This transformation occurs through techniques that create mathematical representations that capture the relationships between the words and their meanings based on context and usage patterns.
Let’s now examine each step of this process.
Normalization
In the context of NLP, normalization is the process of standardizing the text to reduce variability. For example, we may have the following sentence:
The quick brown fox jumps over the lazy dog.
All letters would be converted to lowercase to ensure consistency. For example, “Dog” would become “dog”. Any punctuation marks are removed when they don’t convey meaning. For example, “hello!” at the end of a sentence would become “hello”.
Tokenization
Tokenization is the process of breaking down a sentence into individual words or tokens. The sentence we used above would be broken into an array of tokens that is similar to this:
["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog."]Stop-word removal
Stop-words are common words that carry little semantic value, like “the”, “is”, “at”, etc. For example, if we had the following tokens at the beginning:
["the", "quick", "brown", "fox"]We would be left with the following array after this step is completed:
["quick", "brown", "fox"]The article “the” has been removed.
Stemming and lemmatization
Both stemming and lemmatization reduce the words to their base root form. Stemming achieves this by truncating the words by removing their suffixes. For example, both the words “running” and “runner” become “run”.
Lemmatization is a technique of using a vocabulary to convert different-sounding forms of a word into the base form of that word. For example, this technique would convert the word “went” into its base form “go”.
These are the primary text pre-processing steps. However, we are still dealing with text, which machine learning algorithms cannot understand. Therefore, we will need to convert the text into its numeric representation by using the feature extraction technique.
But this isn’t all. Stemmed word tokens are meaningless to language models. Machines don’t understand text, even though they seem like they do. They only understand numbers. And the unique numeric values that represent the text token are known as features.
Extracting features from text tokens
When dealing with text data, we must convert it into numerical form before any analysis or modeling can occur. Feature extraction bridges the gap between human language and a machine-readable format.
Now that we have a list of words after doing all the pre-processing steps, we need to convert them into numerical representations. One of the simplest methods is the Bag-of-Words model, which counts how many times each word appears in a sentence, ignoring grammar and word order.
For example, we can create a set of all unique words from both sentences and represent each sentence as a vector of word counts. Each number corresponds to the frequency of a word in the sentence. While straightforward, this method doesn’t capture the context or relationships between words. The following figure demonstrates how items are placed into a bag-of-words.
To address this limitation, we can use Term Frequency-Inverse Document Frequency (TF-IDF), which weighs words by their importance, considering how often they appear in a sentence (term frequency) and how unique they are across all sentences (inverse document frequency). This approach emphasizes rare but meaningful words while downplaying common ones, making it useful when dealing with large documents where some words are very common. The process is summarized below:
For a deeper understanding of semantic relationships, we turn to word embeddings. These map words to multi-dimensional vectors that capture meanings and relationships. Popular models like Word2Vec and GloVe assign similar vectors to words with similar meanings. For instance, “cat” and “feline” might have vectors that are close together in space. Sentence embeddings extend this idea to entire sentences, representing them as single vectors that capture context and meaning. Models like Sentence-BERT consider the order and context of words, making them particularly useful for tasks like measuring sentence similarity.
The following diagram summarizes how word embedding is used to determine word similarity.
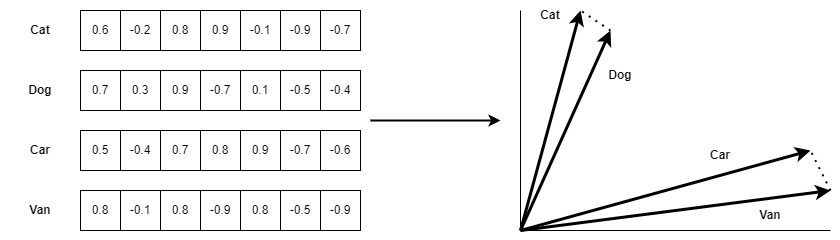
We don’t need to go into details about how any of these models work. However, knowing how these models work would be essential if you want to build an advanced AI chatbot, like ChatGPT. Or, if you are curious about how these LLM models work under the hood and how a computer program can hold a conversation almost as fluently as a real person would, you may want to explore these models more deeply.
Wrapping up
In essence, NLP is the toolkit that empowers machines to “read” and “write” in human languages. As NLP technology continues to evolve, we’re seeing it transform industries by automating communication, generating insights from text data, and even augmenting creativity through tools that write and converse with surprising fluency.
But before you go, here’s an announcement. If you want to learn more about machine learning, including deep learning, NLP, and computer vision, then you may want to get a copy of my book, which is currently available in early access. It’s primarily designed for programmers who already know how to write code, but don’t necessarily know anything about AI, data science, or machine learning.
Moreover, the book doesn’t just explain the theory. It takes you through some practical examples. You will build your own AI models, including an intelligent AI assistant that can execute free-text commands!
The book can be obtained via the link below.
Machine Learning for C# Developers Made Easy
Next time, we will cover the subject of LLM hallucinations: why they are unavoidable, how to minimize them, and how to work around them. So, stay tuned!