
Integrating Ollama container and Semantic Kernel with .NET Aspire


I previously wrote about how to integrate an Ollama container with Semantic Kernel. For those who haven’t read the article, here’s a quick recap.
Ollama is a technology that enables you to host large language models (LLMs), such as Meta’s Llama and DeepSeek, inside an ordinary Docker container. Essentially, by using this technology, you can build your own version of ChatGPT while hosting the entire model yourself.
Semantic Kernel is a collection of .NET libraries that enable you to integrate LLM functionality with any .NET code. It can work with a wide range of LLMs, including the ones hosted by Ollama.
In my previous article, I integrated Semantic Kernel with Ollama container in a locally executed console app. I added some fancy functionality, like streaming the chat answer letter by letter instead of returning the whole text.
This time, we will integrate Ollama and Semantic Kernel with .NET Aspire, which will bring it much closer to how these technologies are likely to be used in real enterprise-grade applications. The samples we will go through are from the following repo, which demonstrates how to build a fully functioning ChatGPT clone, complete with both the hosted model and the in-browser UI:
https://github.com/fiodarsazanavets/dotnet-aspire-examples/tree/main/ChatGptClone/ChatGptClone
In the next article in the series, we will look at the other parts of the functionality, such as building the chat UI and enabling streaming the answers letter-by-letter by using SignalR. But first, let’s get the fundamentals right. In this article, we will focus on the process of hosting an Ollama container inside .NET Aspire and configuring Semantic Kernel as the LLM client in an Aspire-hosted web application.
If you are new to .NET Aspire, you can find several articles about it in my blog. It’s essentially a development stack in .NET for building cloud-first distributed applications.
So, let’s begin!
Installing Ollama dependencies
In .NET Aspire, containerized dependencies are managed in two ways:
Directly via containers
Via the special libraries known as Aspire Integrations (formerly known as Aspire Components)
Aspire Integrations often act as wrappers for containers. The idea is that, for any infrastructure component, you would have a special library where component-specific setup logic is already implemented. If such a library doesn’t yet exist for the component you are looking to integrate, you work with the container directly and implement any required logic yourself.
Luckily for us, Ollama has its own Aspire Integration library! While it’s done via a community toolkit rather than an official component made by Microsoft, it still works perfectly. So we will use that.
To get started, you just need to add the following NuGet package reference to your .NET Aspire host project:
CommunityToolkit.Aspire.Hosting.OllamaNext, we will need to set up the start-up code in the Aspire host. Here’s an example I use inside the AppHost.cs file in the abovementioned project:
var builder = DistributedApplication.CreateBuilder(args);
var ollama = builder.AddOllama("ollama")
.WithLifetime(ContainerLifetime.Persistent)
.WithDataVolume()
.WithOpenWebUI();
var phi35 = ollama.AddModel("phi35", "phi3.5");
builder.AddProject<Projects.ChatGptClone_Web>("webfrontend")
.WithExternalHttpEndpoints()
.WithHttpHealthCheck("/health")
.WaitFor(phi35)
.WithReference(phi35);
builder.Build().Run();Let’s break this code down step-by-step.
We first create a standard distributed app builder for .NET Aspire and assign it to the
buildervariable.We then create an Ollama container with the following configuration:
Ensure that the container uses a persistent lifetime, so it doesn’t have to be restarted every time the app is restarted, and we don’t have to wait for a large model to be re-downloaded.
We store the persistent state in local data volumes via the
WithDataVolume()ivocation.We then add a web-based ChatGPT-like UI for interacting with the Ollama container by invoking the
WithOpenWebUI()method.
We add a model to Ollama via the
AddModel()method. We can add any model we want that Ollama supports. In this example, I chose phi3.5 because it’s one of the smallest. It’s “only” 2 GB, compared to several hundred GB for Meta’s flagship Llama model. The first parameter of the method is the arbitrary name we assigned to the resource. The second parameter is the actual model name.We then pass our model’s reference into a web app via the
WithReference()method. Since the web app depends on the model for its core functionality, we also pass the model reference into theWaitFor()method, ensuring that the web app won’t start until the model is fully downloaded and launched.
Now, if we launch our application, we should have four items displayed in the dashboard:
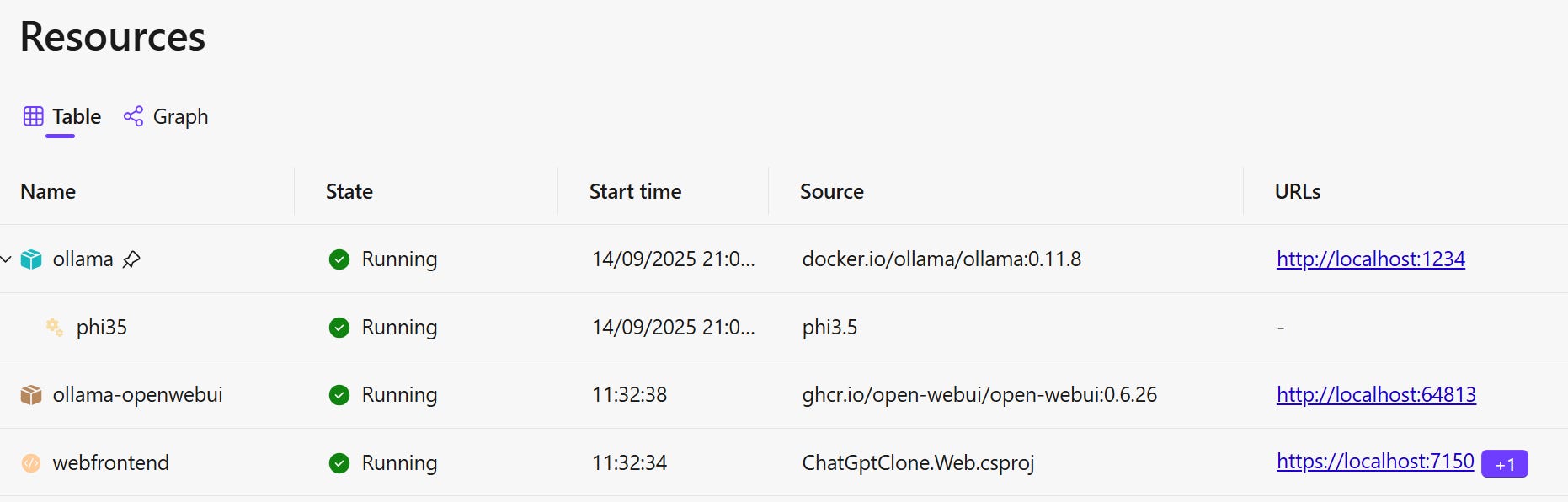
Please note the phi3.5 model will take a while to download when you launch the app for the first time. You can monitor its progress by hovering over it. Both the custom UI app (webfrontend) and Ollama Open Web UI (ollama-openwebui) will be launched after the model has been downloaded and launched.
If you navigate to the Ollama Open Web UI, it provides a user interface very similar to what you may be familiar with via ChatGPT:
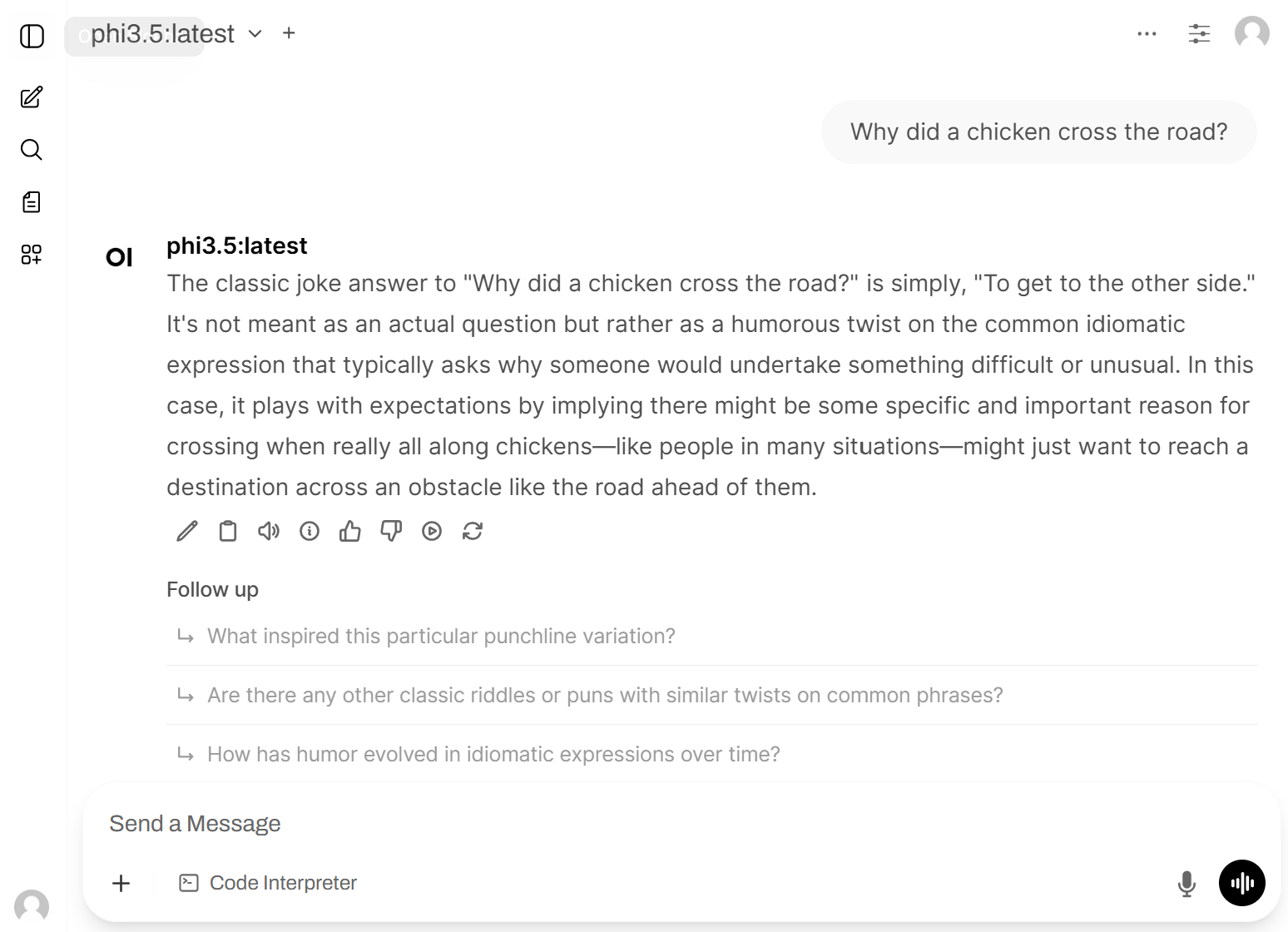
In a way, we are already done building a ChatGPT clone. However, we came here to learn how to integrate chat completion functionality with our .NET-based AI agents and not just do what ChatGPT can already do. Therefore, our next step will be to integrate our setup with Semantic Kernel.
Integrating .NET Aspire with Semantic Kernel
In the example .NET Aspire setup, the ChatGptClone.Web project represents the web application. This is the project we will add the Semantic Kernel to. The NuGet package we need to install is this:
Microsoft.SemanticKernel.Connectors.OllamaPlease note that, at the time of writing, this package is in preview. Therefore, in order to install it, you need to include packages with pre-release versions.
We will then go to the Program.cs file of the project and add the following two namespace references:
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;Now comes the tricky part. We need to use the service discovery mechanism provided by .NET Aspire to resolve the address of the Ollama container, as Semantic Kernel connects to Ollama via its URI or IP address. So, how do we do it?
With many services, we can just pass the container reference into the application and register a HttpClient instance with service discovery enabled, like this:
builder.Services.AddHttpClient("ollama", c =>
{
c.BaseAddress = new Uri("http://ollama");
})
.AddServiceDiscovery();In this case, the http://ollama URL (which is based on the assumption that the name we gave to our Ollama container is ollama) is resolved at runtime to the actual IP address of the Ollama container. However, this doesn’t work with the Ollama community toolkit (at least, not at the time of writing).
This community toolkit wasn’t originally designed to work with Semantic Kernel. Instead, the main client for it was the OllamaSharp library, represented by the CommunityToolkit.Aspire.OllamaSharp NuGet package in the .NET Aspire ecosystem. And, unlike Semantic Kernel, this library connects to an Ollama-hosted model via a connection string rather than an endpoint URI.
However, the good news is that service discovery works with the connection string. Another good news is that the actual endpoint address can be obtained from the connection string. Here’s how you do it. First, we need to reference the following namespace:
using System.Data.Common;Then, this is how we extract the connection string, which was passed into the service in the .NET Aspire host project as the reference to the phi3.5 model:
var phiConnectionString = builder.Configuration.GetConnectionString("phi35");The phi35 is the arbitrary name we previously gave to the resource that represents our model. The connection string is automatically inserted into the ConnectionStrings section of the settings under the key that matches that name.
Our next step is to extract the endpoint URI from the connection string. This is how we do it:
var csBuilder = new DbConnectionStringBuilder { ConnectionString = phiConnectionString };
if (!csBuilder.TryGetValue("Endpoint", out var ollamaEndpoint))
{
throw new InvalidDataException("Ollama connection string is not properly configured.");
}Then, this is how we pass the endpoint reference into the Semantic Kernel registration:
builder.Services.AddSingleton(sp =>
{
var http = sp.GetRequiredService<IHttpClientFactory>().CreateClient("ollama");
IKernelBuilder kb = Kernel.CreateBuilder();
#pragma warning disable SKEXP0070
kb.AddOllamaChatCompletion(
modelId: "phi3.5",
endpoint: new Uri((string)ollamaEndpoint)
);
#pragma warning restore SKEXP0070
return kb.Build();
});Please note the pragma warning disable statement that we need to make sure our code still works with what, at the time of writing, is still an experimental feature.
Finally, we will need to make sure we register all other dependencies that are needed to make our Semantic Kernel work:
builder.Services.AddSingleton(sp =>
sp.GetRequiredService<Kernel>().GetRequiredService<IChatCompletionService>());That’s it. Our Semantic Kernel is registered and configured to connect to the Ollama container at runtime. Our chat completion functionality is fully enabled in our distributed app.
Wrapping up
Next time, I will show you how to integrate the chat completion service with the web application code. You can already see how it works by examining the repo I linked to at the beginning, but in my next article, I will explain it to make things easier for you.
We will build a streaming chat completion UI where your prompt is sent to the server, and the response is returned to the page asynchronously, letter by letter, just like it happens in ChatGPT. If you want to know how it works, subscribe to my newsletter so you don’t miss it.
Also, from now on, my newsletter will be focused on the AI engineering concepts, i.e., teaching you how AI works and how to integrate it in your applictaion code. There is a new software engineering profession that is currently in high demand — an AI engineer.
This profession combines traditional software engineering skills with AI literacy. This combination of skills is relatively rare, and, therefore, top companies are willing to pay top money to someone who has these skills. In my newsletter, I will be teaching you how to obtain these skills, and this is another reason why you may consider subscribing.
Finally, since we were talking about .NET Aspire today, I am currently writing a book that will teach you how it works. The book is almost completed and is currently in early access. You can have a look at it via this link. It’s heavily discounted while it’s in early access.
All the best, and I’ll see you next time!